“Il futuro è aperto” diceva il filosofo austriaco Karl Popper riferendosi alle conseguenze delle nostre scelte, credendo che non fosse possibile pianificare le future scoperte intellettuali. Se fosse ancora vivo, immaginiamo che davanti all’home page di Google avrebbe esclamato: “Anche il passato è aperto”.
Difatti, questo strumento permette di trovare tantissimi dati che potrebbero –come lui avrebbe affermato– falsificare la propria ipotesi, ossia sottoporla a un infinito processo di controllo che non giunge mai a una verità definita.
Quello che ci fornisce Google, o i suoi equivalenti, consiste in un microscopio rivolto al passato, azzerandoci i costi e i tempi della ricerca tra una sconfinata quantità di dati, e ciò l’ha resa oggi alla portata di tutti.
Resta il tema centrale, cosa cerchiamo in questo spazio aperto e, soprattutto, con quale metodo?
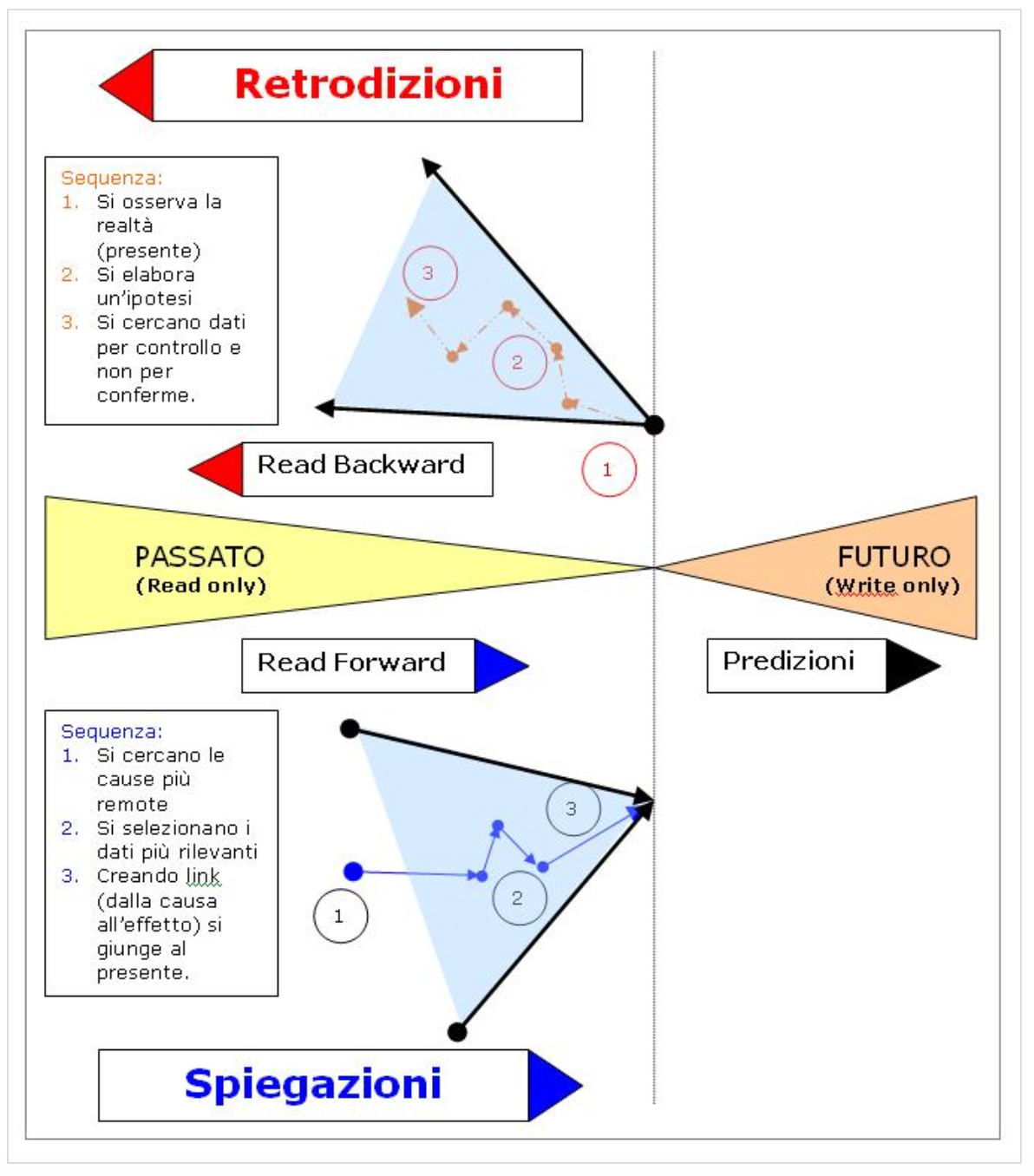
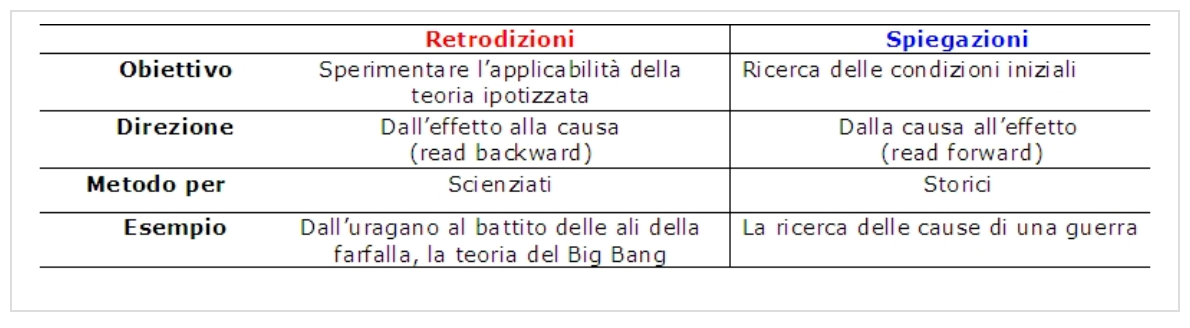
Sappiamo che la predizione è un’affermazione su eventi che riguardano il futuro e che quindi devono ancora avvenire, mentre esistono due particolari metodi per descrivere un evento del passato: la retrodizione e la spiegazione.
La retrodizione è una speculazione su un evento che è accaduto nel passato ma che adesso (nel presente) mostra le sue conseguenze.
La retrodizione però differisce sostanzialmente dalla spiegazione ove, in quest’ultima, le conseguenze sono già evidenti ma deve essere ricostruito il percorso dai dati iniziali e a come si è giunti a tali risultati (è la direzione della storia: read forward).
Per esempio, l’esame con il Carbonio-14 ci dà una retrodizione su quando (in un intervallo) un particolare essere è vissuto nel passato, ed è differente pertanto dalla spiegazione, non ci dice perché quell’evento è accaduto, potrebbe essere una casualità, tutto questo spetta a noi. Dovremmo ricorrere a congetture per capirne le cause delle attuali evidenze.
E’ come se un ragno (spider) cercasse di ricostruire tutti i nodi della ragnatela (web) partendo dal risultato finale (il presente). Le connessioni tra gli eventi (link) esistevano nella realtà del passato, ma oggi anche grazie a questi strumenti, si palesano. Però dobbiamo ripercorrere tutti i passi al contrario (read backward).
In questo modo chiaramente il passato non si trasforma (è read only), ma la nostra migliore interpretazione ci aiuta a comprendere l’evento in oggetto.
Esempio: la morte di Marilyn Monroe.
Per cercare di capirne le cause, navigando tra i dati, potremmo procedere con i seguenti metodi:
Spiegazione
Regola: Un eccesso di sonnifero porta alla morte
Ipotesi: MM ha preso molto sonnifero
Risultato: MM è morta.
Si parte dalle cause sempre più lontane per descrivere -o meglio spiegare- l’evento finale.
Possono esserci però anche differenti spiegazioni: altri medicinali, droghe, pratiche mediche scorrette, ecc. Oppure delle combinazioni di questi elementi.
C’è poi un’altra consistente spiegazione che si rifà a preesistenti condizioni di malattie dell’artista e alle sue debolezze psicologiche derivanti da un’infanzia difficile. È naturale questo processo, e i migliori studiosi (storici) partono dalle cause più remote e con dovizia di particolari tentano di spiegare -con una coerenza interna alle proposizioni- come si è arrivati alla morte.
Retrodizione
Regola: Un eccesso di sonnifero porta alla morte
Risultato: MM è morta
Ipotesi: MM ha preso molto sonnifero.
In questo caso si prende in considerazione una regola nota, si osserva il risultato e si formula un’ipotesi dalla quale sia possibile evincere il fatto stesso. Può non essere l’unica ipotesi, non si raggiunge la certezza, ma aggiunge conoscenza alla nostra analisi.
* * *
La disponibilità dei dati è una condizione necessaria per la verifica empirica, ma non è una condizione sufficiente. Pensiamo spesso che più risultati troviamo più abbiamo ragioni di credere che le nostre ipotesi siano corrette. Ma sembrano corrette, non lo sono certamente.
Non è la quantità dei dati disponibili una misura per valutare la bontà di una ipotesi, ma è la precisione con la quale si può scoprire anche un solo dato che conferma se la teoria ipotizzata è plausibile o fallace.
Ormai i dati sono tutti disponibili per ognuno di noi, ma non basta una mera raccolta e la risposta poi la troveremo lì, pronta. Perché l’intelligenza artificiale (AI), ad oggi, non riesce a individuare dai dati le cause che scatenano gli eventi.
Anche se i motori di ricerca ci presentano i risultati in varie forme, però poi occorre selezionare i dati alla ricerca della:
– causa remota del fatto osservato (la causa in rapporto alle conseguenze)
– teoria alla base dell’evento (il fatto in rapporto all’ipotesi).
È quest’opera di valutazione che, svolta nell’immenso rumore di fondo, conferisce un ordine e un’anima ai dati.
Il poeta T.S. Eliot, già nel 1934, ci aveva avvertito del pericolo di perdersi tra l’eccesso di dati con la poesia The Rock:
Dov’è la saggezza
che abbiamo perso in conoscenza?
Dov’è la conoscenza
che abbiamo perso in informazione?
Oggi si potrebbe aggiungere:
Dov’è l’informazione
che abbiamo perso tra i dati?
Come rappresentato in figura, oggi si possono scorgere due ombre che si proiettano nel passato.
C’è in natura un unico filtro capace di separarle, illuminarle e nello stesso tempo estrarre informazioni da quei dati: l’intelligenza umana, ora aumentata.


