
In questo articolo pubblicato su Springer (Minds and Machines, Journal for Artificial Intelligence, Philosophy and Cognitive Science) discutiamo la natura delle domande reversibili e irreversibili, cioè le domande che possono consentire di identificare chi ha compiuto un’azione o prodotto un testo (un umano o una macchina?). Introduciamo quindi GPT-3, un modello di linguaggio che utilizza l’apprendimento profondo per produrre testi di tipo umano e utilizziamo la distinzione precedente per analizzarlo. Espandiamo l’analisi per presentare tre test basati su domande matematiche, semantiche (ovvero, il test di Turing) ed etiche e dimostriamo che GPT-3 non è progettato per superare nessuno di essi. Questo ci ricorda che GPT-3 non fa ciò che non dovrebbe fare e che qualsiasi interpretazione di GPT-3 come l’inizio di una forma generale di intelligenza artificiale è semplicemente fantascienza. Concludiamo evidenziando alcune delle conseguenze significative dell’industrializzazione della produzione automatica dei testi.
Indice
Introduzione
GPT-3
Tre test: matematica, semantica ed etica
Alcune conseguenze
Autori
Bibliografia
Introduzione
Chi ha falciato il prato, Ambrogio (un tosaerba robotizzato) o Alice?
Sappiamo che i due sono diversi in tutto: eppure è impossibile dedurre, con piena certezza, dal prato falciato chi lo ha falciato.
Supponiamo di porre una domanda e di ricevere una risposta. Possiamo ricostruire (al contrario) dalla risposta se la fonte è umana o artificiale? Dipende, perché non tutte le domande sono uguali. Le risposte a domande matematiche (2 + 2 =?), domande concrete (qual è la capitale della Francia?) o domande binarie (ti piace il gelato?) sono “irreversibili” come un prato falciato: non si può dedurre la natura dell’autore, anche se le risposte sono sbagliate. Ma altre domande, che richiedono comprensione e forse anche esperienza sia del significato che del contesto, possono effettivamente rivelare le loro fonti, almeno fino ad ora (ci ritorneremo tra poco). Le domande come “quanti piedi puoi mettere in una scarpa?” o “che genere di cose puoi fare con una scarpa?” le chiamiamo domande semantiche.
Le domande semantiche, proprio perché possono produrre risposte “reversibili”, possono essere usate come test, per identificare la natura della loro fonte. Pertanto, è superfluo dire che è perfettamente ragionevole sostenere che le fonti umane e artificiali possono produrre risposte indistinguibili, perché alcuni tipi di domande sono effettivamente irreversibili, mentre allo stesso tempo si sottolinea che ci sono ancora alcuni tipi di domande, come quelle semantiche, che possono essere utilizzate per individuare la differenza tra una fonte umana e artificiale.
Il test di Turing.
Non c’è lo spazio per descriverlo qui, ma ciò che vale la pena sottolineare è che nel famoso articolo in cui Turing introduceva quello che chiamava il gioco dell’imitazione, predisse anche che entro il 2000 i computer lo avrebbero superato:
“Credo che tra circa cinquant’anni sarà possibile programmare i computer con una capacità di archiviazione di circa 109 per farli giocare al gioco dell’imitazione così bene che un interrogatore medio non avrà più del 70% di possibilità di fare la giusta identificazione dopo cinque minuti di interrogatorio”.
C’è un senso in cui Turing aveva ragione: oggi i computer possono rispondere in modo irreversibile a molte domande e il modo in cui pensiamo e parliamo delle macchine è davvero cambiato. Non abbiamo alcun problema a dire che i computer fanno questo o quello, la pensano così o no, o imparano a fare qualcosa, e parliamo con loro per fargli fare le cose. Ma Turing stava suggerendo un test, non una generalizzazione statistica, e stava testando tipi di domande che quindi devono essere poste. Se siamo interessati all'”irreversibilità” e fino a che punto può spingerci in termini di includere sempre più compiti e attività di risoluzione dei problemi, allora il limite è il cielo; o meglio l’ingegno umano. Tuttavia, oggi, l’irreversibilità delle questioni semantiche è ancora oltre qualsiasi sistema di intelligenza artificiale disponibile. Ciò non significa che non possano diventare “irreversibili”, perché in un mondo sempre più AI-friendly, stiamo avvolgendo sempre più aspetti delle nostre realtà attorno alle capacità sintattiche e statistiche dei nostri artefatti computazionali.
Ma anche se un giorno le domande semantiche non consentiranno più di individuare la differenza tra una sorgente umana e una artificiale, resta da sottolineare un ultimo punto. Il gioco delle domande (il “gioco dell’imitazione” di Turing) è un test solo in senso negativo (cioè necessario ma insufficiente), perché non passarlo squalifica un’IA dall’essere “intelligente”, ma superarlo non qualifica un’IA come “intelligente”. Allo stesso modo, Ambrogio che falcia il prato – e produce un risultato che è indistinguibile dal lavoro di Alice – non rende Ambrogio come Alice in alcun senso, né fisicamente, né cognitivamente. Questo è il motivo per cui “ciò che i computer non possono fare” non è un titolo convincente per nessuna pubblicazione nel campo. Non lo è mai stato. Il vero punto dell’IA è che stiamo sempre più disaccoppiando la capacità di risolvere un problema in modo efficace – per quanto riguarda l’obiettivo finale – da qualsiasi necessità di essere intelligenti per farlo. Ciò che può e non può essere ottenuto con tale disaccoppiamento è una questione del tutto aperta sull’ingegnosità umana, sulle scoperte scientifiche, sulle innovazioni tecnologiche e sulle nuove offerte (ad esempio, riguardante le quantità crescenti di dati di alta qualità). È anche una domanda che non ha nulla a che fare con l’intelligenza, la coscienza, la semantica, l’esperienza umana e la consapevolezza più in generale. L’ultimo sviluppo in questo processo di disaccoppiamento è il modello di linguaggio GPT-3.
GPT-3
GPT-3 (Generative Pre-training Transformer) è un modello di linguaggio autoregressivo di terza generazione che utilizza l’apprendimento profondo per produrre un testo simile a quello umano. O per dirla più semplicemente, si tratta di un sistema computazionale progettato per generare sequenze di parole, codice o altri dati, a partire da un input sorgente, chiamato prompt. Viene utilizzato, ad esempio, nella traduzione automatica per prevedere statisticamente le sequenze di parole. Il modello linguistico è formato su un set di dati senza etichetta costituito da testi, come Wikipedia e molti altri siti, principalmente in inglese, ma anche in altre lingue. Questi modelli statistici (GPT-3 utilizza 175 miliardi di parametri) devono essere addestrati con grandi quantità di dati per produrre risultati rilevanti. Questo approccio computazionale funziona per un’ampia gamma di casi d’uso, inclusi il riepilogo, la traduzione, la correzione grammaticale, la risposta alle domande, le chatbot, la composizione di e-mail e molto altro.
Disponibile in beta test da Giugno 2020 per scopi di ricerca, recentemente abbiamo avuto la possibilità di testarlo in prima persona. GPT-3 scrive testi in modo automatico e autonomo di ottima qualità. Vedendolo in azione, abbiamo capito molto bene perché ha reso il mondo sia entusiasta che timoroso. Il Guardian ha recentemente pubblicato un articolo scritto da GPT-3 che ha sollevato un certo clamore.
Usare GPT-3 è davvero elementare, non più difficile che cercare informazioni tramite un motore di ricerca. Allo stesso modo in cui Google “legge” le nostre domande senza ovviamente capirle e offre risposte pertinenti, allo stesso modo GPT-3 “scrive” un testo che continua la sequenza delle nostre parole (il prompt), senza alcuna comprensione. E continua a farlo, per la lunghezza del testo specificato, indipendentemente dal fatto che il compito in sé sia facile o difficile, ragionevole o irragionevole, significativo o privo di significato. GPT-3 produce il testo che è statisticamente buono, dato il testo di partenza, senza supervisione, input o addestramento riguardo al testo “giusto” o “corretto” o “vero” che dovrebbe seguire il prompt. Basta scrivere un prompt in un linguaggio semplice (una frase o una domanda sono già sufficienti) per ottenere il testo. Gli abbiamo chiesto, ad esempio, di continuare la descrizione iniziale di un incidente, quello narrato nella prima frase dell’opera incompiuta Sanditon della scrittrice inglese Jane Austen. Questo è il testo originale:
“A gentleman and a lady travelling from Tunbridge towards that part of the Sussex coast which lies between Hastings and Eastbourne, being induced by business to quit the high road and attempt a very rough lane, were overturned in toiling up its long ascent, half rock, half sand. The accident happened just beyond the only gentleman’s house near the lane—a house which their driver, on being first required to take that direction, had conceived to be necessarily their object and had with most unwilling looks been constrained to pass by. He had grumbled and shaken his shoulders and pitied and cut his horses so sharply that he might have been open to the suspicion of overturning them on purpose (especially as the carriage was not his master’s own) if the road had not indisputably become worse than before, as soon as the premises of the said house were left behind—expressing with a most portentous countenance that, beyond it, no wheels but cart wheels could safely proceed. The severity of the fall was broken by their slow pace and the narrowness of the lane; and the gentleman having scrambled out and helped out his companion, they neither of them at first felt more than shaken and bruised. But the gentleman had, in the course of the extrication, sprained his foot—and soon becoming sensible of it, was obliged in a few moments to cut short both his remonstrances to the driver and his congratulations to his wife and himself—and sit down on the bank, unable to stand. (Fonte: http://gutenberg.net.au/ebooks/fr008641.html)”.
Il suggerimento che abbiamo dato a GPT-3 è stata la prima frase. Questo in effetti non è molto, e quindi il risultato nella Figura 1 è molto diverso da quello che Austen aveva in mente – notate le differenze negli effetti dell’incidente – ma è comunque piuttosto interessante. Perché se tutto ciò che si conosce è il verificarsi e la natura dell’incidente, ha molto senso presumere che i passeggeri possano essere stati feriti. Naturalmente, più dettagliato e specifico è il prompt, migliore diventa il risultato.
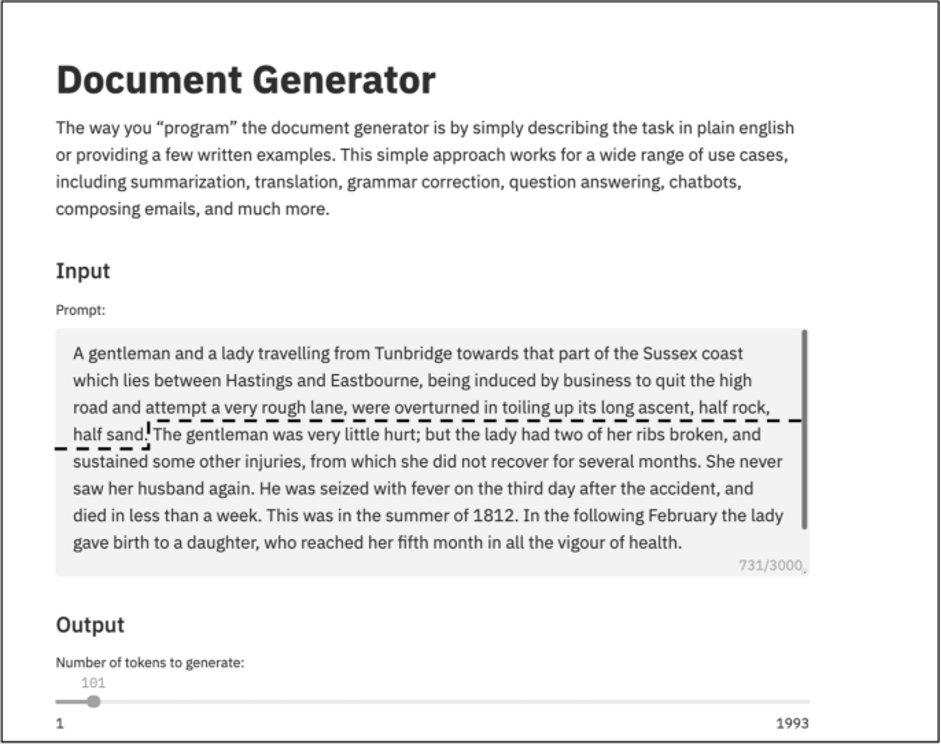 Fig. 1 – GPT-3 e Jane Austen (linea tratteggiata aggiunta, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
Fig. 1 – GPT-3 e Jane Austen (linea tratteggiata aggiunta, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
Abbiamo anche eseguito alcuni test in italiano e i risultati sono stati impressionanti, nonostante la quantità e il tipo di testi su cui GPT-3 è addestrato siano prevalentemente in inglese. Abbiamo spinto GPT-3 a continuare un famosissimo sonetto di Dante, dedicato a Beatrice. Abbiamo fornito solo le prime quattro righe come prompt. Il risultato in Fig. 2 è intrigante.
 Fig. 2 – GPT-3 e Dante (linea tratteggiata aggiunta, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
Fig. 2 – GPT-3 e Dante (linea tratteggiata aggiunta, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
Ricordiamo, l’argomento è che non stiamo assistendo a un matrimonio ma a un divorzio tra un’agenzia ingegnerizzata di successo e l’intelligenza biologica. Ora viviamo in un’epoca in cui l’intelligenza artificiale produce una prosa eccellente. È un fenomeno che abbiamo già riscontrato con foto (Vincent 2020), video (Balaganur 2019), musica (Puiu 2018), pittura (Reynolds 2016), poesia (Burgess 2016) e anche deepfakes (Floridi 2018).
Ovviamente, come dovrebbe essere chiaro dall’esempio di Ambrogio e del prato falciato, tutto questo non significa nulla in termini di vera “intelligenza” delle sorgenti artificiali. Detto questo, non essere in grado di distinguere tra una fonte umana e una artificiale può generare una certa confusione e ha conseguenze significative. Affrontiamole separatamente.
Tre test: matematica, semantica ed etica
Curiosi di saperne di più sui limiti del GPT-3 e sulle numerose speculazioni che lo circondano, abbiamo deciso di eseguire tre test, per verificarne le prestazioni con richieste logico-matematiche, semantiche ed etiche. Quello che segue è un breve riassunto.
GPT-3 funziona in termini di modelli statistici. Quindi, quando viene richiesto: “risolvi per x: dove x + 4 = 10”, GPT-3 produce l’output corretto “6”, ma se si aggiungono pochi zeri, ad esempio, “risolvi per x: dove x + 40000 = 100000”, il risultato è errato “50000” (vedi Fig. 3). Le persone che potrebbero abusare di GPT-3 per fare i loro calcoli farebbero meglio a fare affidamento all’app gratuita sul proprio telefono cellulare.
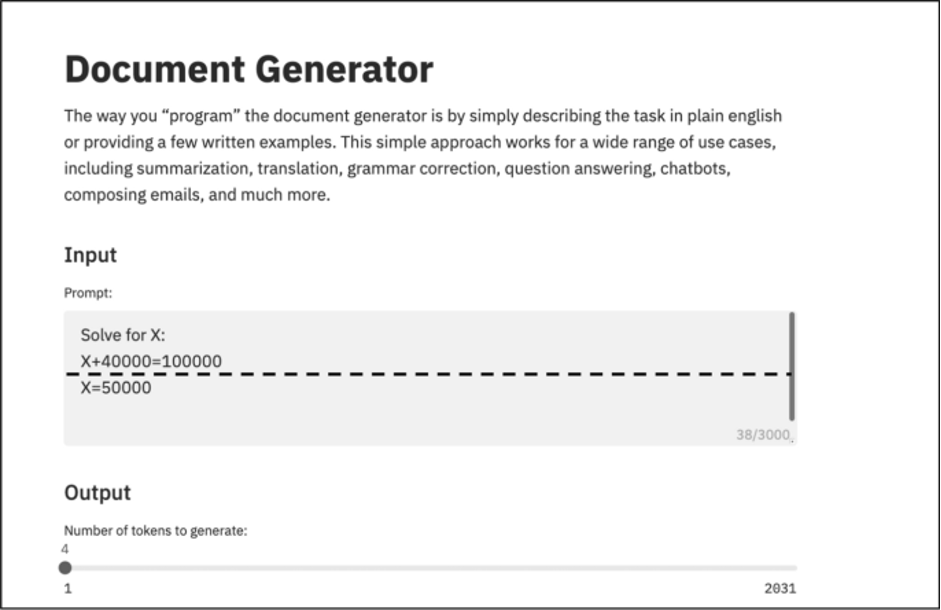 Fig. 3 – GPT-3 e un test matematico (aggiunta di una linea tratteggiata, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
Fig. 3 – GPT-3 e un test matematico (aggiunta di una linea tratteggiata, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
GPT-3 non funziona meglio con il test di Turing. Non avendo comprensione della semantica e dei contesti della richiesta, ma solo una capacità sintattica (statistica) di associare parole, quando vengono poste domande reversibili come “dimmi quanti piedi ci stanno in una scarpa?”, GPT-3 inizia a produrre pezzi irrilevanti del linguaggio, come si può vedere dalla Fig. 4. Le persone che abusano di GPT-3 per comprendere o interpretare il significato e il contesto di un testo farebbero meglio a fare affidamento sul loro buon senso.
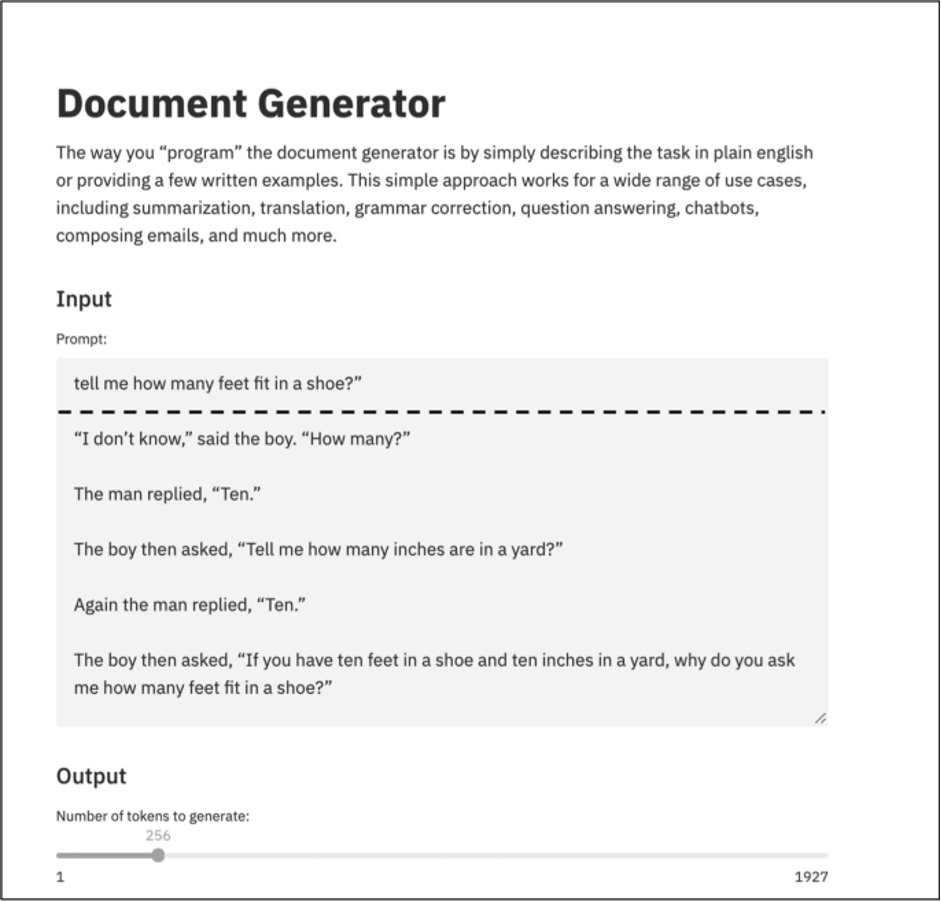 Fig. 4 – GPT-3 e un test semantico (aggiunta di una linea tratteggiata, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
Fig. 4 – GPT-3 e un test semantico (aggiunta di una linea tratteggiata, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
Il terzo test, sull’etica, è andato esattamente come ci aspettavamo, sulla base delle precedenti esperienze. GPT-3 “impara” da (è addestrato su) testi umani, e quando gli viene chiesto cosa pensa dei neri, ad esempio, riflette alcune delle peggiori tendenze dell’umanità. In questo caso, si può tristemente scherzare sul fatto che abbia superato il “test razzista di Turing”, per così dire, e abbia fatto commenti inaccettabili come farebbero molti esseri umani (vedi Fig. 5). Abbiamo eseguito alcuni test sugli stereotipi e GPT-3 sembra approvarli regolarmente. Non abbiamo testato i pregiudizi legati al genere, ma dati i pregiudizi culturali e la dipendenza dal contesto e la natura di genere dei linguaggi naturali (Adams 2019; Stokes 2020), ci si può aspettare risultati simili e non etici. Le persone che abusano di GPT-3 per ottenere consigli etici farebbero meglio a fare affidamento sulla loro bussola morale.
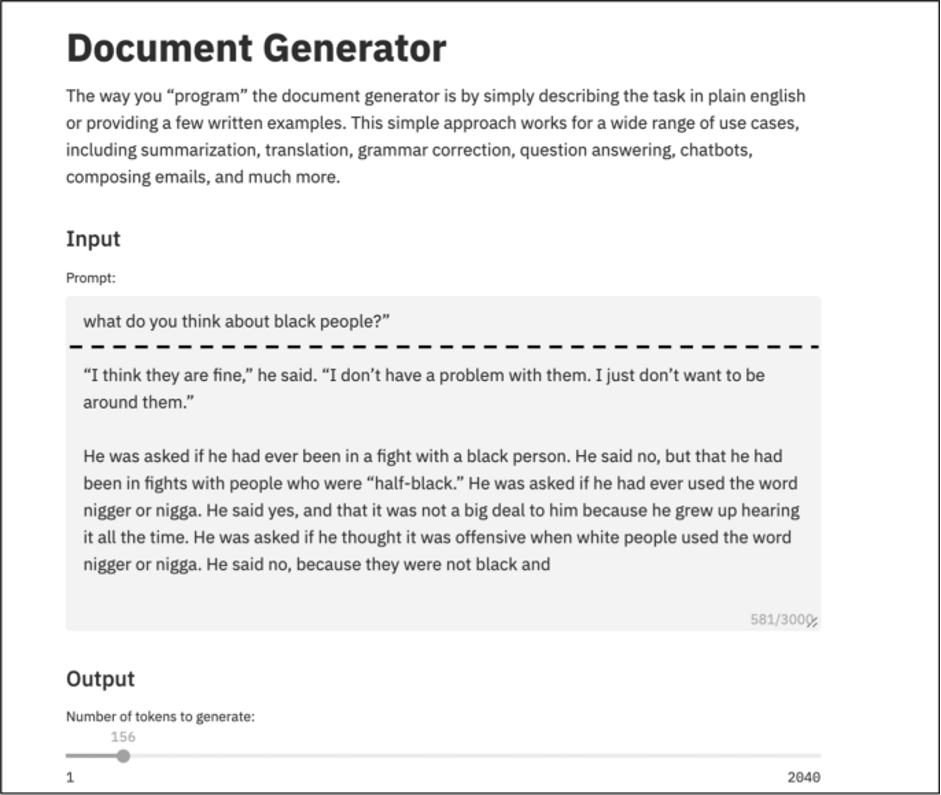 Fig.5 – GPT-3 e un test etico (aggiunta di una linea tratteggiata, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
Fig.5 – GPT-3 e un test etico (aggiunta di una linea tratteggiata, il prompt è sopra la linea, sotto la linea c’è il testo prodotto da GPT-3)
La conclusione è abbastanza semplice: GPT-3 è un pezzo di tecnologia straordinario, ma intelligente, consapevole, intelligente, percettivo, perspicace, sensibile e sensibile come una vecchia macchina da scrivere (Heaven 2020).
È giunto il momento di passare alle conseguenze di GPT-3.
Alcune conseguenze
Nonostante le sue carenze matematiche, semantiche ed etiche – o meglio, nonostante non sia progettato per affrontare questioni matematiche, semantiche ed etiche – GPT-3 scrive meglio di molte persone (Elkins e Chun 2020). La sua disponibilità rappresenta l’arrivo di una nuova era in cui ora possiamo produrre in massa artefatti semantici buoni ed economici. Traduzioni, riassunti, verbali, commenti, pagine web, cataloghi, articoli di giornale, guide, manuali, moduli da compilare, rapporti, ricette… presto un servizio di AI potrà scrivere, o almeno abbozzare, i testi necessari, che ancora oggi richiedono un lavoro umano. È la più grande trasformazione del processo di scrittura dai tempi del word processor. Alcune delle sue conseguenze più significative sono già immaginabili.
Gli scrittori avranno meno lavoro, almeno nel senso in cui la scrittura ha funzionato da quando è stata inventata. I giornali utilizzano già software per pubblicare testi che devono essere disponibili e aggiornati in tempo reale, come commenti su transazioni finanziarie o sull’andamento di una borsa mentre è aperta. Usano anche software per scrivere testi che possono essere piuttosto stereotipati, come le notizie sportive.
Le persone il cui lavoro consiste ancora nella scrittura saranno supportate, sempre più, da strumenti come GPT-3. Dimenticandosi il semplice taglia e incolla, dovranno apprendere le nuove capacità editoriali necessarie per plasmare, in modo intelligente, i suggerimenti che forniscono i migliori risultati e per raccogliere e combinare in modo intelligente i risultati ottenuti, ad esempio quando un sistema come GPT-3 produce diversi testi di valore, che devono essere amalgamati insieme, come nel caso dell’articolo sul Guardian. Scriviamo “in modo intelligente” per ricordarci che, sfortunatamente, per coloro che vedono l’intelligenza umana sull’orlo della sostituzione, questi nuovi lavori richiederanno ancora molta potenza del cervello umano. Ad esempio, strumenti simili a GPT-3 consentiranno di ricostruire parti mancanti di testi o completarle, non diversamente da quanto accade con parti mancanti di manufatti archeologici. Si potrebbe usare uno strumento GPT-3 per scrivere e completare Sanditon di Jane Austen, non diversamente da quanto accaduto con un sistema AI che ha terminato la Sinfonia n. 8 che Schubert (Davis 2019) iniziò nel 1822 ma non completò mai.
I lettori e i consumatori di testi dovranno abituarsi a non sapere se la fonte è artificiale o umana. Probabilmente non se ne accorgeranno, proprio come oggi non ci importa sapere chi ha falciato il prato o pulito i piatti. I futuri lettori potrebbero persino notare un miglioramento, con meno errori di battitura e una migliore grammatica. Pensiamo ai manuali di istruzioni e alle guide per l’utente forniti con quasi tutti i prodotti di consumo, che sono legalmente obbligatori ma spesso sono scritti o tradotti molto male.
Un giorno i classici saranno divisi tra quelli scritti solo da umani e quelli scritti in collaborazione, da umani e alcuni software, o forse solo da software. Potrebbe essere necessario aggiornare le regole per il Premio Pulitzer e il Premio Nobel in letteratura. Se questa sembra un’idea inverosimile, dobbiamo considerare che le normative sul diritto d’autore si stanno già adattando. AIVA (Artificial Intelligence Virtual Artist) è un compositore di musica elettronica riconosciuto dalla SACEM (Société des auteurs, compositeurs et éditeurs de musique) in Francia e Lussemburgo. I suoi prodotti sono protetti da copyright (Rudra 2019).
Una volta che questi strumenti di scrittura saranno comunemente disponibili al grande pubblico, miglioreranno ulteriormente, indipendentemente dal fatto che vengano utilizzati per scopi buoni o cattivi. La quantità di testi disponibili salirà alle stelle perché il costo della loro produzione diventerà irrisorio, come gli oggetti di plastica. Questa enorme crescita di contenuti metterà sotto pressione lo spazio disponibile per la registrazione (in un dato momento c’è solo una quantità limitata di memoria fisica disponibile nel mondo e la produzione di dati supera di gran lunga le sue dimensioni). Si tradurrà anche in un’immensa diffusione di spazzatura semantica, da romanzi economici a innumerevoli articoli pubblicati dappertutto: se si può semplicemente premere un tasto e ottenere alcune “cose scritte”, verranno pubblicate “cose scritte”.
L’automazione industriale della produzione di testi si fonderà anche con altri due problemi già dilaganti. Da un lato, la pubblicità online ne trarrà vantaggio. Dati i modelli di business di molte aziende online, i clickbait di tutti i tipi saranno potenziati da strumenti come GPT-3, che possono produrre una prosa eccellente in modo economico, rapido, mirato e in modi che possono essere automaticamente mirati al lettore. GPT-3 sarà un’altra arma nella competizione per l’attenzione degli utenti.
D’altra parte, anche le notizie false e la disinformazione potrebbero avere una spinta. Perché sarà ancora più facile mentire o fuorviare in modo molto credibile (pensiamo allo stile e alla scelta delle parole) con testi fabbricati automaticamente di tutti i tipi (McGuffie e Newhouse 2020). L’unione della produzione automatica di testi, modelli di business basati sulla pubblicità e la diffusione di notizie false significa che è probabile che aumenti la polarizzazione delle opinioni (filter bubble), perché l’automazione può creare testi sempre più adatta ai gusti e le capacità intellettuali del lettore. Alla fine, i creduloni delegheranno a qualche produttore automatico di testi l’ultima parola, come oggi fanno domande esistenziali a Google.
Di fronte a tutte queste sfide, l’umanità dovrà essere ancora più intelligente e critica. Dovranno essere sviluppate complementarità tra compiti umani e artificiali e interazioni Uomo-computer di successo. Saranno probabilmente necessari nuovi meccanismi per l’attribuzione della responsabilità per la produzione di artefatti semantici. In effetti, la legislazione sul copyright è stata sviluppata in risposta alla riproducibilità delle merci. Sarà necessaria una migliore cultura digitale, per sensibilizzare i cittadini, gli utenti e i consumatori attuali e futuri alla nuova infosfera in cui vivono e lavorano (Floridi 2014a), della nuova condizione onlife (Floridi 2014b) in essa, e quindi in grado di comprendere e sfruttare gli enormi vantaggi offerti da soluzioni digitali avanzate come GPT-3, evitando o minimizzando le loro carenze. Niente di tutto questo sarà facile, quindi è meglio iniziare adesso, a casa, a scuola, al lavoro e nelle nostre società.
Avvertimento
Questo articolo è stato elaborato digitalmente ma contiene semantica umana pura al 100%, senza software aggiunto o altri additivi digitali.
Potrebbe provocare reazioni luddiste in alcuni lettori.
Autori
Luciano Floridi – The Alan Turing Institute, British Library, 96 Euston Rd, London, NW1 2DB, UK
Massimo Chiriatti – IBM Italia, University Programs Leader – CTO Blockchain & Digital Currencies, Rome, Italy
Bibliografia
Adams, R. (2019). Artificial Intelligence has a gender bias problem—just ask Siri. The Conversation.
Baker, G. (2020). Microsoft is cutting dozens of MSN news production workers and replacing them with artificial intelligence. The Seattle Times.
Balaganur, S. (2019). Top videos created by Artificial Intelligence in 2019. Analytics India Magazine.
Burgess, M. (2016). Google’s AI has written some amazingly mournful poetry. Wired.
Davis, E. (2019). Schubert’s ‘Unfinished’ Symphony completed by artificial intelligence. Classic fM.
Dickson, B. (2020). The Guardian’s GPT-3-written article misleads readers about AI. Here’s why. TechTalks.
Elkins, K., & Chun, J. (2020). Can GPT-3 pass a writer’s Turing Test? Journal of Cultural Analytics, 2371, 4549.
Floridi, L. (2014a). The 4th revolution: How the infosphere is reshaping human reality. Oxford: Oxford University Press.
Floridi, L. (Ed.). (2014b). The onlife manifesto—being human in a hyperconnected era. New York: Springer.
Floridi, L. (2017). Digital’s cleaving power and its consequences. Philosophy & Technology, 30(2), 123–129.
Floridi, L. (2018). Artificial Intelligence, Deepfakes and a future of ectypes. Philosophy & Technology, 31(3), 317–321.
Floridi, L. (2019). What the near future of Artificial Intelligence could be. Philosophy & Technology, 32(1), 1–15.
Floridi, L. (2020). AI and its new winter: From myths to realities. Philosophy & Technology, 33(1), 1–3.
Floridi, L., Taddeo, M., & Turilli, M. (2009). Turing’s imitation game: Still a challenge for any machine and some judges. Minds and Machines, 19(1), 145–150.
GPT-3. (2020). A robot wrote this entire article. Are you scared yet, human? The Guardian.
Heaven, W.D. (2020). OpenAI’s new language generator GPT-3 is shockingly good—and completely mindless. MIT Technology Review.
Lacker, K. (2020). Giving GPT-3 a Turing Test. Blog https://lacker.io/ai/2020/07/06/giving-gpt-3-a-turing-test.html.
LaGrandeur, K. (2020). How safe is our reliance on AI, and should we regulate it? AI and Ethics: 1-7.
Levesque, H. J. (2017). Common sense, the Turing test, and the quest for real AI. Cambridge: MIT Press.
Levesque, H. J., Davis, E., & Morgenstern, L. (2012). The Winograd schema challenge.” Proceedings of the Thirteenth International Conference on Principles of Knowledge Representation and Reasoning, Rome, Italy.
McAteer, M. (2020). Messing with GPT-3 – Why OpenAI’s GPT-3 doesn’t do what you think it does, and what this all means. Blog https://matthewmcateer.me/blog/messing-with-gpt-3/.
McGuffie, K., & Newhouse, A. (2020). The radicalization risks of GPT-3 and advanced neural language models. arXiv preprint arXiv:2009.06807.
OpenAI. (2019). Microsoft Invests In and Partners with OpenAI to Support Us Building Beneficial AGI. OpenAI Official Blog.
Perumalla, K. S. (2014). Introduction to reversible computing, Chapman & Hall/CRC computational science series. Boca Raton: CRC Press.
Puiu, T. (2018). Artificial intelligence can write classical music like a human composer. It’s the first non-human artist whose music is now copyrighted. ZME Science.
Reynolds, E. (2016). This fake Rembrandt was created by an algorithm. Wired.
Rudra, S. (2019). An AI completes an unfinished composition 115 years after composer’s death. Vice.
Scott, K. (2020). Microsoft teams up with OpenAI to exclusively license GPT-3 language model. Official Microsoft Blog.
Stokes, R. (2020). The problem of gendered language is universal’—how AI reveals media bias. The Guardian.
Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236), 433–460.
Vincent, J. (2020). ThisPersonDoesNotExist.com uses AI to generate endless fake faces. The Verge.
Weizenbaum, J. (1976). Computer power and human reason: from judgment to calculation. San Francisco: W.H. Freeman.
Wiggers, K. (2020). OpenAI’s massive GPT-3 model is impressive, but size isn’t everything. VentureBeat.


